Apache Kafka® is a message queueing technology that is used for distributed event streaming.
Kafka captures data in real-time from event sources like microservices in the form of streams of events. It stores these event streams in ‘topics’ for later consumption. Kafka is typically installed alongside ZooKeeper. ZooKeeper has five primary functions. Specifically, ZooKeeper is used for controller election, cluster membership, topic configuration, access control lists, and quotas.
We will use the Confluent platform to deploy Kafka, zookeeper and a graphic console.
Now that our cluster is ready and we have downloaded the kubeconfig file, let’s verify that our cluster is up and running. To verify that you have a running master and worker node, list the nodes by executing:
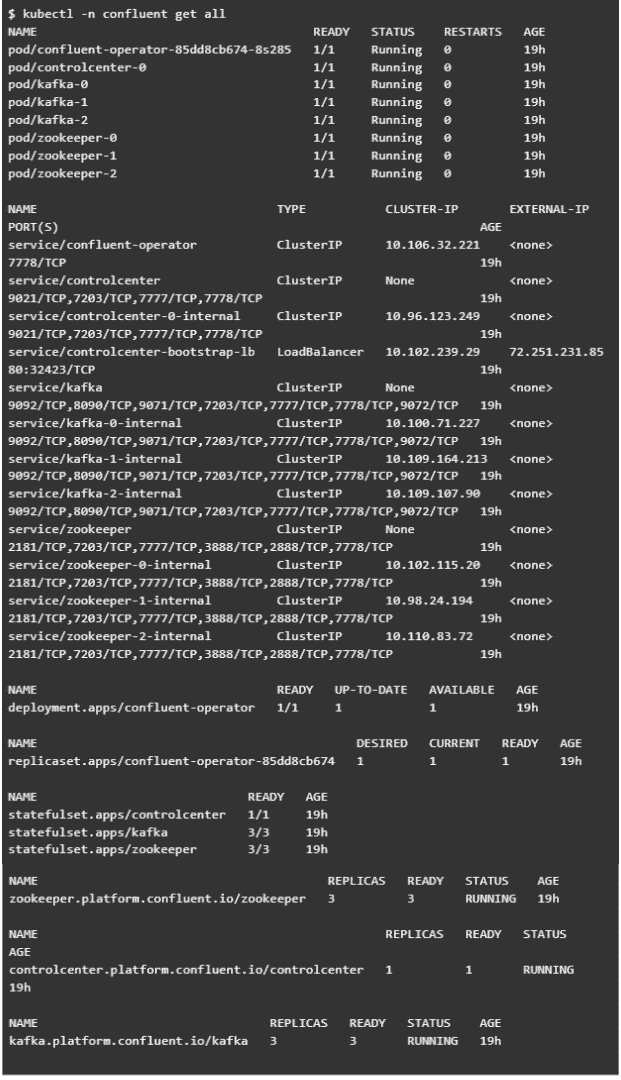
If everything works, you should something similar to this:
Now we are ready to deploy Confluent®.
Deploying Confluent® with Helm
We will be using Helm to install an operator for Confluent. Confluence adds custom resource definitions (CRDs) and you use the resources to define what you need the operator to take care of. First, add the Confluent helm repo and update it.
Next, add the CRDs to kubectl. Download the plugin. Unpack the kubectl plugin that matches your client environment (Linux, Windows or Mac OS (Darwin)) into your client environment local executables directory. This will allow the kubectl to find the plugin. For example, on Linux:








 Cloud U.Enroll in higher education at Ridge University
Cloud U.Enroll in higher education at Ridge University